Case Study
Support Operations Dashboard
Dieser Case zeigt, wie unstrukturierte Support- und Operations-Aufgaben in einen sichtbaren, priorisierten Workflow übersetzt werden können.
Worum ging es konkret?
In Support- und Operations-Umgebungen entstehen Probleme oft nicht durch fehlende Arbeit, sondern durch fehlende Sichtbarkeit. Es ist unklar, welche Aufgabe dringend ist, wer verantwortlich ist, was als Nächstes passieren muss und ob ein Vorgang bereits blockiert oder eskaliert ist.
Der Demo-Case nutzt eine fiktive interne Support-Situation bei Rheintal Systems AG. Die Tickets decken typische Business-Application- und Operations-Themen ab: Benutzerzugriff, Datenimport, Berichtsdifferenzen, Produktdaten und System-Synchronisation.
Der Fokus liegt nicht auf einem bestimmten Tool, sondern auf der Logik dahinter: Status, Priorität, Verantwortlichkeit, nächste Aktion und Eskalation.
Was war das operative Problem?
Eine Support-Meldung ist allein noch kein steuerbarer Vorgang. Sie braucht Kontext: Was ist das Problem, wie kritisch ist es, wer übernimmt es, was ist die nächste Aktion und bis wann muss sie erledigt sein?
Ohne diese Struktur werden Tickets leicht zu einer offenen Liste. Dringende Themen können zwischen normalen Aufgaben verschwinden, Rückmeldungen bleiben aus und Eskalationen werden zu spät sichtbar.
Die zentrale Frage war daher: Wie wird aus einem unklaren Aufgabenstrom ein kontrollierter Support-Workflow?
Wie wurde der Workflow strukturiert?
01
Raw Ticket Input
Support- und Operations-Themen werden zuerst als einzelne Einträge sichtbar: Zugriff, Datenimport, Berichtsdifferenz, fehlende Produktdaten oder System-Sync-Fehler.
02
Strukturierter Tracker
Jeder Eintrag erhält Status, Priorität, Owner, Fälligkeit, nächste Aktion und Eskalationshinweis. Dadurch wird aus einer losen Aufgabenliste ein steuerbarer Workflow.
03
Dashboard View
Die wichtigsten Signale werden zusammengeführt: offene Tickets, wartende Vorgänge, Eskalationen, SLA-Risiko und gelöste Aufgaben.
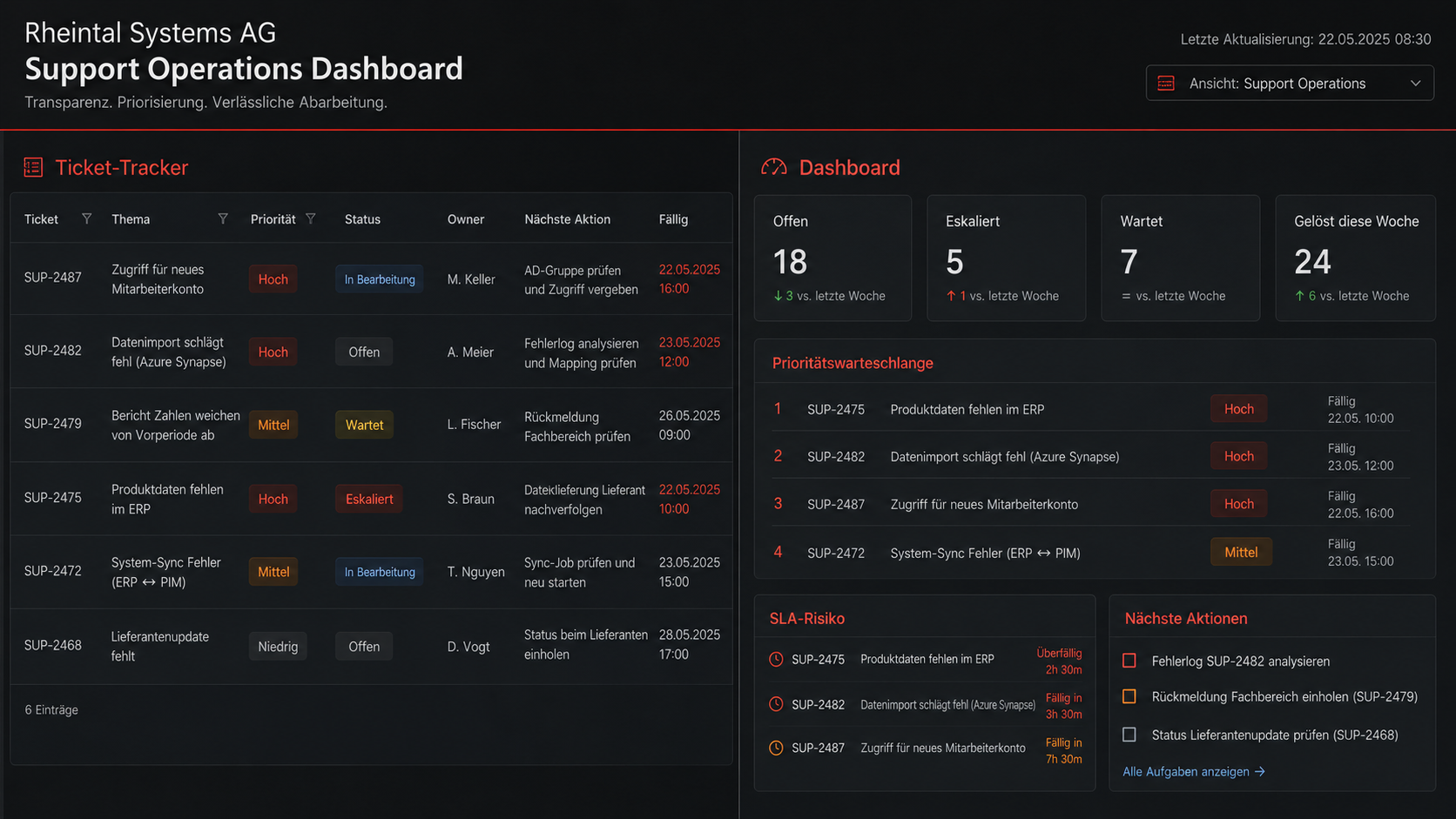
Was zeigt der Tracker?
Der Tracker zeigt die operative Rohstruktur. Jeder Vorgang bekommt eine klare Zeile mit Ticket-ID, Thema, Priorität, Status, Owner, nächster Aktion, Fälligkeit, Eskalation und letztem Update.
Dadurch wird sichtbar, ob ein Thema offen, in Bearbeitung, wartend, eskaliert oder abgeschlossen ist. Die nächste Aktion ist entscheidend, weil sie verhindert, dass Aufgaben nur dokumentiert werden, aber operativ stehen bleiben.
Der Tracker ist bewusst einfach gehalten. Er bildet die Grundlogik ab, die später auch in professionellen Ticketing-Tools wie Jira Service Management, Freshservice oder ServiceNow wiederzufinden ist.
Was zeigt das Dashboard?
Das Dashboard übersetzt die Tracker-Daten in eine Management- und Support-Ansicht. Statt jede Zeile einzeln zu lesen, werden die wichtigsten Signale sichtbar: offene Tickets, eskalierte Vorgänge, wartende Rückmeldungen, gelöste Aufgaben und SLA-Risiko.
Besonders wichtig ist die Prioritätswarteschlange. Sie zeigt, welche Tickets zuerst bearbeitet werden müssen und welche nächste Aktion jeweils erforderlich ist.
Damit wird aus einem statischen Ticketbestand ein aktiver Arbeitsvorrat.
Was dieser Case zeigt
Dieser Case zeigt die Fähigkeit, unstrukturierte Support- und Operations-Themen in eine klare Arbeitslogik zu übersetzen: priorisieren, verantworten, nachverfolgen, eskalieren und sichtbar machen.